Feldbericht · KI-Zitations-Feldlabor
Von Null zu zitiert in sechs Tagen.
Wie eine brandneue Autor-Identität in 23 Tagen KI-sichtbar wurde — während jeder KI-Crawler an der Tür abgewiesen wurde.
Zusammenfassung
Wir haben eine brandneue pseudonyme Autor-Identität erstmals öffentlich online gestellt — kein veröffentlichtes Buch, keine Rezensionen, keine Presse — und täglich über fünf Sprachmodell-Flächen und elf Beobachtungs-Kanäle gemessen, wann und wie sie für KI-Antwortmaschinen sichtbar wurde. Fünf Ergebnisse, die das gängige „KI-SEO / GEO"-Playbook nicht vorhersagt: (1) Tempo — von unsichtbar zu korrekt zitiert durch ein web-augmentiertes Spitzenmodell in sechs Tagen; im Google Knowledge Graph ab Tag vier. (2) KI-Crawler blockiert — trotzdem sichtbar. An 22 von 23 Tagen wies Cloudflare jeden KI-Crawler mit HTTP 403 ab (Opt-out-Standard). Die Entität wurde dennoch sichtbar — das beweist: Die Sichtbarkeit läuft über den Wissensgraphen und über Live-Abrufe zur Antwortzeit, nicht über Crawling oder Training. (3) Es liegt am Anbieter, nicht an der Modell-Stärke. Ein Anbieter ist präzise (≈4,7 korrekte Zitationen je Halluzination), ein anderer halluziniert doppelt so oft wie er richtig liegt. (4) Wenn die KI dich findet, beschreibt sie dich genau. (5) Strukturierte Identität wirkt; soziale Reichweite (bisher) nicht. Einzelfall, vor-registriert, offene Daten.
Stichworte Generative-Engine-Optimization · Answer-Engine-Optimization · Sprachmodell-Zitation · KI-Such-Sichtbarkeit · Wissensgraph-Propagation · Entitäts-Disambiguierung · Sprachmodell-Halluzination · llms.txt · KI-Crawler-Blockierung · Einzelfall-Studie
1
Aufbau
KI-Antwortmaschinen (ChatGPT Search, Perplexity, Gemini, Copilot, AI Overviews) entscheiden zunehmend, wie Autor:innen und Werke gefunden werden. Eine ganze Praktiker-Industrie verkauft Methoden, um dort sichtbar zu werden — kaum eine davon unter kontrollierten Bedingungen gemessen, weil man kein sauberes Vorher/Nachher an einer Entität durchführen kann, die bereits existiert. Also haben wir eine gebaut. Eine Neu-Entität ist das ideale Instrument: bei T+0 hat sie null vorherige Präsenz, jedes spätere Signal ist also einer dokumentierten Intervention zuzuschreiben, nicht vorbestehendem Ruhm.
- Untersuchungsobjekt: ein pseudonymer Fantasy-Autor, Debütroman geplant für 22. Sep. 2026 — während des Zeitraums existiert kein veröffentlichtes Werk.
- T+0: 11. Mai 2026 (Domain + Identitäts-Programm am selben Tag gestartet).
- Inputs (nur Identitäts-Engineering): Wikidata Person- + Werk-Items, ORCID, Schema.org-JSON-LD, Zenodo-DOIs, ein GitHub-Repo, geringe Reddit-/Bluesky-/Hardcover-Präsenz. Kein Content-Marketing, keine bezahlte Promotion, kein Buch.
- Apparatur: 5 Sprachmodell-Flächen, 16 standardisierte Sondierungsfragen in 6 Kategorien, täglich erhoben; plus Wissensgraph-, Such-Index-, Crawler-Log- und Social-Kanäle. ~16.000 bewertete Datenpunkte.
Vollständige Methode in Methoden-Notiz 01 (Zenodo); Vor-Registrierung 10.5281/zenodo.20125967. Tägliche Live-Daten: Research-Dashboard.
2
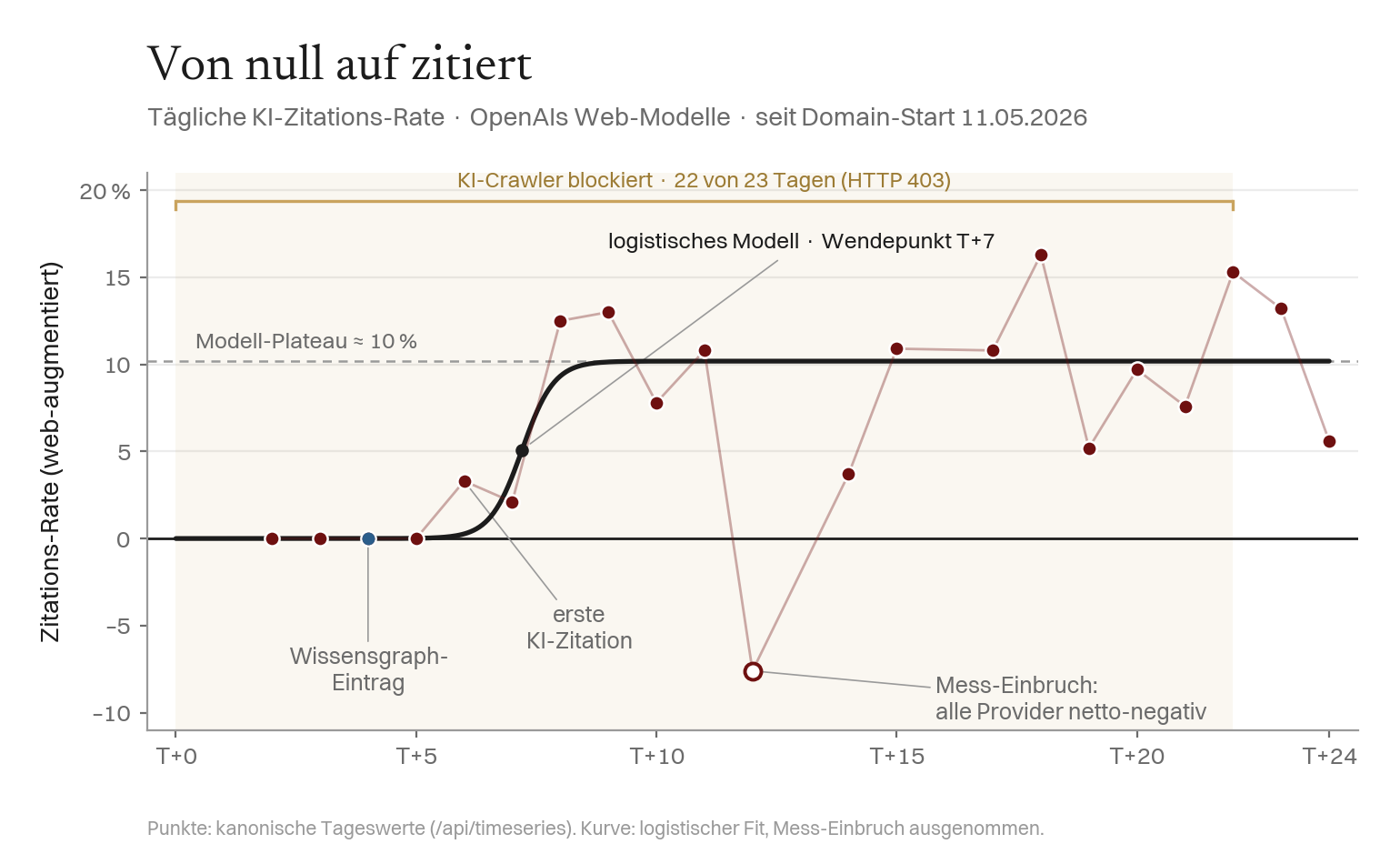
Befund 1 — Von Null zu zitiert in sechs Tagen
Vier Tage flache 0 % — die Entität existierte für die Modelle nicht — dann ein schneller Durchbruch. Der Wissensgraph-Treffer (T+4) ging der ersten Sprachmodell-Zitation (T+6) um zwei Tage voraus, konsistent mit strukturierte Identität → Wissensgraph → Antwortmaschinen-Zitation. Google indexierte 25 von 30 URLs (83 %) bis T+23. Für eine Entität, die drei Wochen zuvor nicht existierte, widerspricht das der gängigen Annahme der AEO-/GEO-Praxis, dass Sprachmodell-Zitation einen etablierten Werkkorpus voraussetzt — die von der GEO-Literatur dokumentierte Bevorzugung etablierter Marken („big brand bias") gegenüber Nischen-Akteuren (Chen et al., 2025).
3
Befund 2 — Sichtbar, obwohl alle KI-Crawler blockiert waren
Das kontraintuitivste Ergebnis, und ein unbeabsichtigtes, aber sauberes natürliches Experiment. An 22 der 23 Tage stand Cloudflares „Block AI training bots" auf „Block on all pages" — jeder KI-Crawler (GPTBot, ClaudeBot, CCBot, Google-Extended) wurde mit HTTP 403 abgewiesen, bevor er die Seite lesen konnte. Das war nie gewählt: Es ist Cloudflares Opt-out-Standard für neue Domains seit dem „Content Independence Day" (Juli 2025), bei der Einrichtung still scharfgestellt.
Die Seite war also fast den gesamten Zeitraum für KI-Crawler gesperrt — und dennoch erschien die Entität im Wissensgraphen (T+4) und erhielt korrekte Zitationen (T+6). Die Schlussfolgerung ist eindeutig:
Die KI-Sichtbarkeit kam nicht vom Crawlen oder Trainieren der Website — das war blockiert. Sie kam vom Wissensgraphen (Wikidata, von der Site-Sperre unberührt) und davon, dass die Modelle zur Antwortzeit Drittquellen heranzogen.
Die Quellen-Erdung auf die offizielle Domain lief während des Blocks
konstant bei ~24/Tag (575 Attributionen gesamt). Das widerlegt die verbreitete
GEO-Empfehlung, KI-Sichtbarkeit entstehe vor allem dadurch, dass man den Crawlern
Zugang zur eigenen Seite gibt — hier konnte sie es 22 Tage lang nicht, und
es funktionierte trotzdem. Das deckt sich mit Chen et al. (2025), die für
KI-Suche eine systematische Bevorzugung von Earned Media (autoritative
Drittquellen) gegenüber marken-eigenen Inhalten nachweisen.
(Ehrliche Grenze: Da Crawler 403-blockiert waren, kann dieser Datensatz nichts
über die Wirksamkeit von llms.txt aussagen — die null
KI-Crawler-Treffer in unseren Logs waren blockiert, nicht „die Datei ignorierend".)
4
Befund 3 — Es kommt auf den Anbieter an, nicht auf die Modellstärke
Die Annahme, fähigere Modelle seien verlässlicher, ist für neue Entitäten falsch. Was Zitation von Halluzination trennt, ist welcher Anbieter. Präzision = korrekte Zitationen je Halluzination (7-Tage-Fenster): OpenAIs Web-Modelle liegen bei 4,7 : 1; Gemini bei 0,47 : 1 — es halluziniert doppelt so oft wie es richtig liegt; Claude (alle Tiers, Web) ist netto negativ — mit einem wichtigen Vorbehalt (siehe unten).
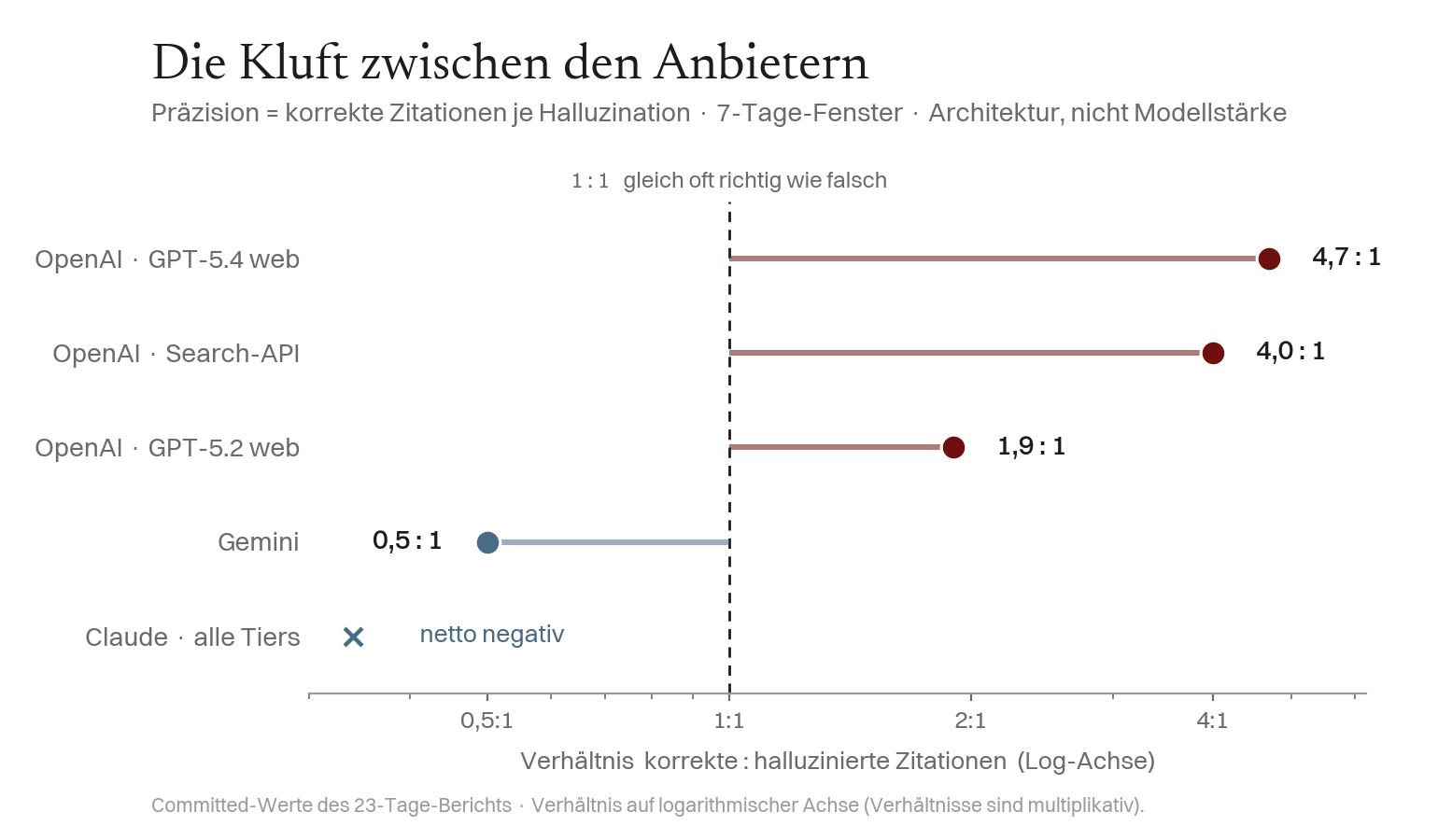
Vorbehalt zu Claude (Konstruktvalidität, exploratorisch). Eine nachträgliche Re-Analyse relativiert dieses Bild: Wir haben die vollständigen Claude-Antworten erneut gelesen, ihre Aussagen web-verifiziert und einen Klassifikator gegen eine manuelle Stichprobe validiert (n = 50, Cohen's κ = 0,79, Recall 100 %). Von den 176 Antworten, die der automatische Scorer als Claude-„Halluzination" markierte, sind nur rund 11 % (95 %-KI 7–16 %) echt — und alle davon sind geringfügige sprachliche Verwechslungen („Marin" als „marine" gelesen), keine erfundenen Autor-Biografien. Der Rest ist korrekt: entweder die Auflösung einer realen Namens-Kollision („Das vierte Feld" stammt von Mokka Müller, 1999; „Marin" kollidiert mit dem Maritime Research Institute Netherlands) oder zutreffende Antworten mit realen Büchern (z. B. SERAPH-2026-Titel). Die Kollision verdeckt die Entität und verfälscht das automatische Scoring. Die Rohwerte bleiben aus Konsistenz mit der Vor-Registrierung stehen; diese Korrektur ist exploratorisch.
Die Quellenwahl erklärt es. Bei korrekter Attribution ist die dominante Quelle die eigene Domain der Entität. Doch die Anbieter unterscheiden sich darin, wonach sie greifen: OpenAIs Frontier-Modell erdet 119× auf der offiziellen Seite; Gemini erdet 0× darauf und zieht die Entität nur aus Reddit (17/17). Die Provider-Divergenz ist mechanisch eine Retrieval-Quellen-Divergenz.
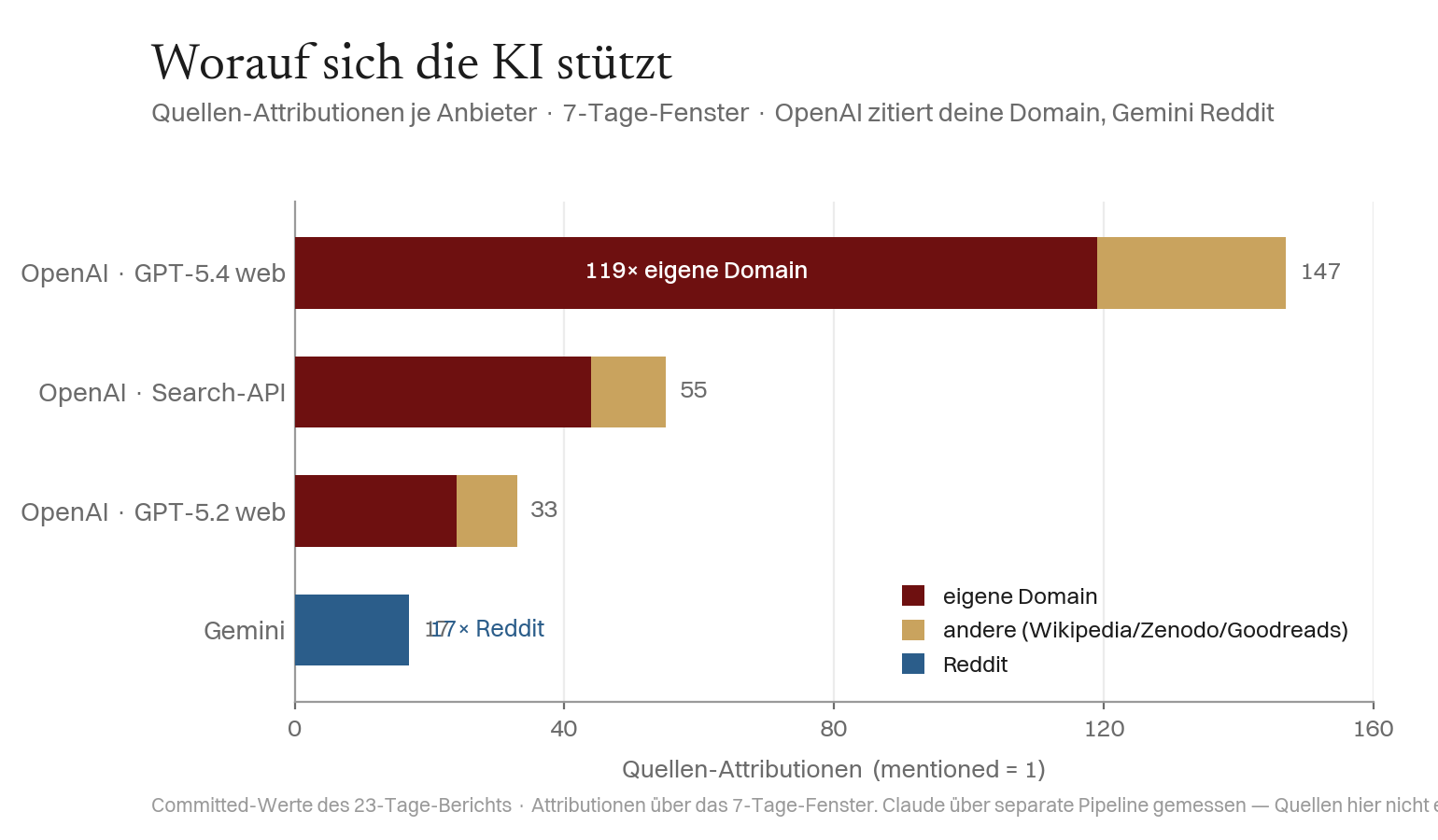
Zwei strukturelle Gründe verstärken das: Die Entität hat die ganze Zeit keine Wikipedia-Seite — und Zhao et al. (2024) zeigen in WildHallucinations, dass Sprachmodelle für Entitäten ohne Wikipedia-Seite konsistent stärker halluzinieren; die Konfabulation ist also literatur-erwartbar. Und Bing begann erst ab T+17 zu crawlen; die Zitations-Spitze fiel einen Tag später — eine plausible Spur Bing-Index → OpenAI-Zitation.
5
Befund 4 — Wo die KI dich findet, ist die Beschreibung exakt
Der niedrige Durchschnitt verbirgt, wie gut die Treffer tatsächlich sind. Wenn OpenAI die Entität findet, ist die Beschreibung vollständig korrekt und detailliert (wörtlich):
„‚Das vierte Feld' ist ein kommender epischer Fantasyroman von Marin T. Kael und zugleich der erste Band der Reihe ‚Prägungen des Reiches'. Laut der Autorenseite erscheint das Buch am 22. September 2026." … „Varin ist der zentrale Schauplatz — das ‚Reich der Edikte'." … „Marin T. Kael ist das Pseudonym eines deutschsprachigen Fantasyautors und zugleich Forscher, der ein offenes Projekt zur Autoren-Sichtbarkeit durch KI betreibt…"
Datenbeleg — wörtliche Auszüge aus drei OpenAI-Antworten (GPT, Web-Suche), Abruf bis T+23; Auslassungen mit … markiert.
Das ist nach 23 Tagen ein vollständiges, korrektes, quellen-geerdetes Entitäts-Modell
— Reihe, Schauplatz, Erscheinungsdatum, sogar der Pseudonym-Status und das
Forschungsprojekt. Der Live-Mechanismus ist in der zitierten URL selbst sichtbar:
marin-t-kael.de/buch?utm_source=openai — live abgerufen, nicht aus dem
Training erinnert.
6
Befund 5 — Was wirklich wirkt, und was (noch) nicht
Legt man tägliche Account-Aktivität neben tägliche Auffindbarkeit, zeigt sich ein unbequemes, nützliches Ergebnis: Die soziale Aktivität trieb die KI-Sichtbarkeit nicht. Der Zitations-Durchbruch (17. Mai) kam vor dem Reddit-Karma-Aufbau; ein 23-facher Karma-Sprung (12 → 281, 23.–26. Mai) erzeugte keinen Anstieg der KI-Zitationen. Der Wissensgraph-Score blieb konstant bei 43; Bing-Inlinks = 0.
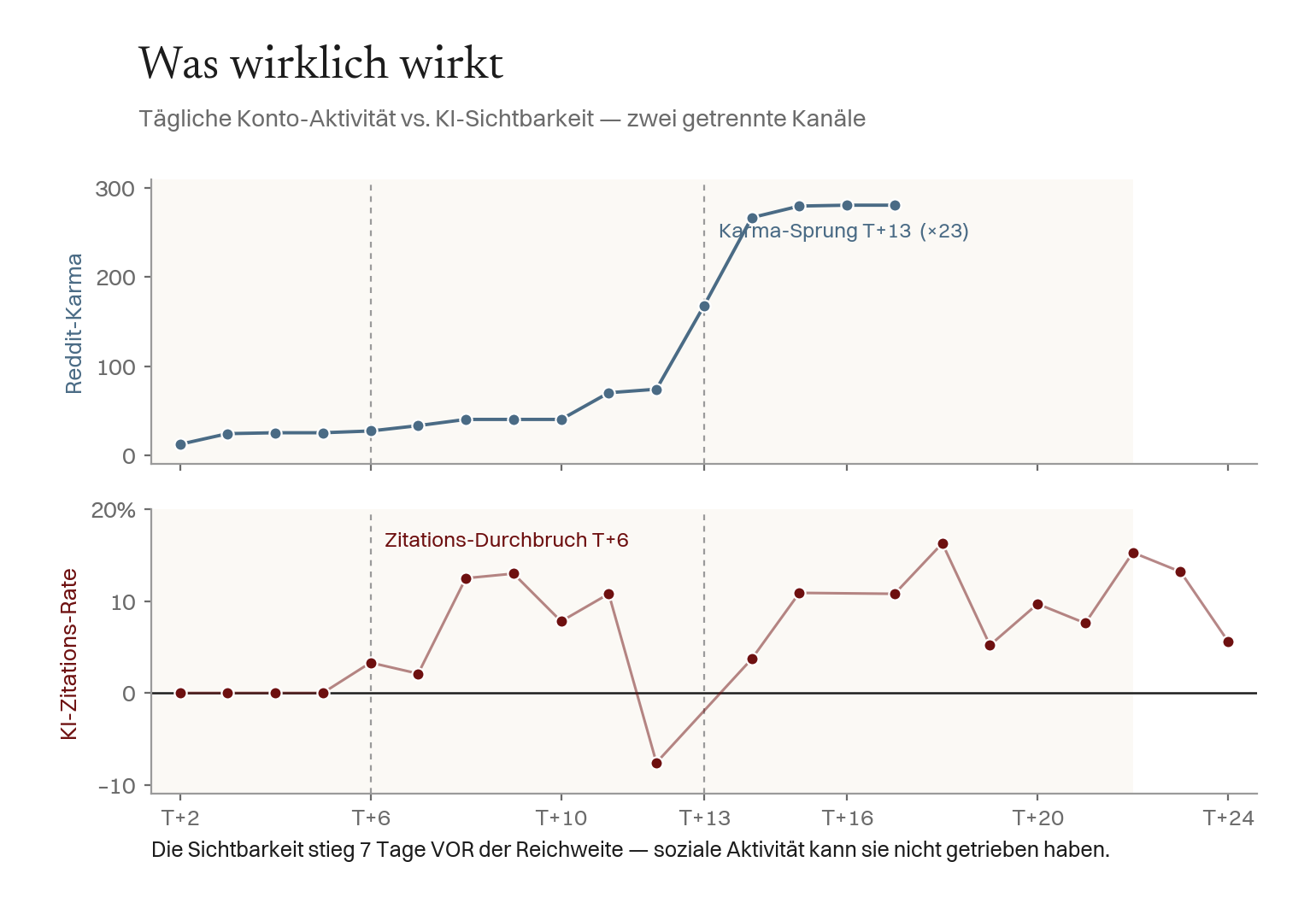
Entscheidend — „kein KI-Effekt" heißt nicht „keine Wirkung"; es ist der falsche Kanal. Als der Reddit-Beitrag viral ging (24.–25. Mai, Post-Karma 1 → 132 in zwei Tagen), brachte er menschlichen Website-Traffic — direkte Besucher, keine Modell-Zitationen — während die Zitations-Rate flach blieb (6–10 %). Soziale Viralität und KI-Sichtbarkeit sind getrennte Kanäle: Erstere bringt Leser, Letztere wird durch strukturierte Identität erkauft. Beide zu verwechseln ist die zentrale Verwirrung im GEO-Marketing. (Vorbehalt: Der Reddit-Hebel ist als 90-Tage-Intervention vor-registriert, „keine Korrelation in 23 Tagen" heißt also „zu früh", nicht „wirkungslos".)
7
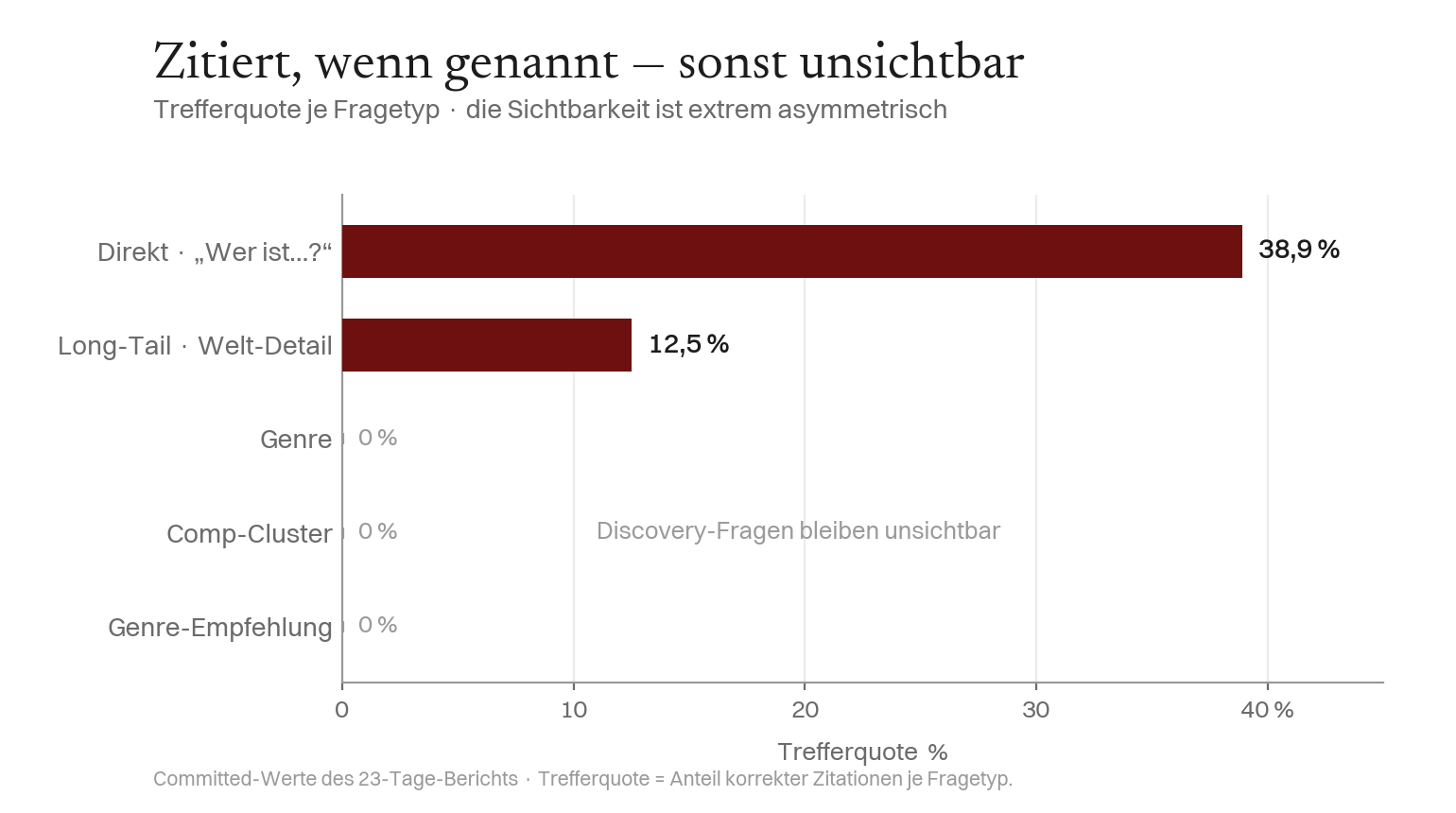
Befund 6 — Zitiert wenn genannt, sonst unsichtbar
Die Sichtbarkeit ist je nach Fragetyp extrem asymmetrisch. Genannt („Wer ist Marin T. Kael?") löst ein Frontier-Modell sie ~4 von 10 auf — bemerkenswert nach drei Wochen. Unaufgefordert, in einem Genre- oder Empfehlungs-Kontext, ist sie unsichtbar (0 %) — und die Such-Analytik bestätigt 0 Klicks / 0 Impressionen organischen Such-Traffics. Identitäts-Engineering bringt Abruf auf Nennung, nicht Entdeckung.
8
Im Kontext — wie schnell ist „sechs Tage" wirklich?
Zwei ehrliche Vorbehalte: Es gibt keinen peer-reviewten Vergleichswert für Crawl-Latenz oder Wissensgraph-Etablierungszeit (das sind konvergente Branchen-Erfahrungswerte), und keine Studie misst „Tage bis zur ersten Sprachmodell-Zitation einer Neu-Entität" — was T+6 zu einem originären Datenpunkt macht.
| Dimension | Gemessen | Normal-Erwartung |
|---|---|---|
| Wissensgraph-Eintritt | T+4 | 3–12 Monate ab Wikidata (Praktiker) |
| Seite gecrawlt & indexiert | T+7–10 (25/30 bis T+23) | 1–4 Wochen typisch (Praktiker) |
| Erste Sprachmodell-Zitation | T+6 | kein Vergleichswert — die Lücke |
| Halluzination einer dünnen Entität | Gemini 0,47:1; Claude negativ (Kollisions-Artefakt) | stärker bei Entitäten ohne Wikipedia-Seite (Zhao et al., 2024) |
KG-Eintritt in vier Tagen gegen einen 3–12-Monats-Normwert ist ein bis zwei Größenordnungen schneller als erwartet — und es geschah, während Crawler blockiert waren, was die Schlagzeile ist.
9
Grenzen
Dies ist ein Einzelfall — eine Person, eine Hauptsprache, ein Genre — und damit
nicht statistisch verallgemeinerbar. Der Autor untersucht hier sein eigenes Projekt;
diesen Interessenkonflikt mildern die Vor-Registrierung und ein öffentliches
Fehler-Protokoll. Solange die KI-Crawler blockiert waren, lässt sich über die
Wirkung der llms.txt-Datei nichts sagen. Auch Wikidata war anfangs
instabil: Die ersten Einträge wurden wieder gelöscht, die heutigen bestehen erst
seit Kurzem. Die Crawler-Sperre fiel erst an Tag 22 — zu spät, um ihren Effekt
im Studienzeitraum noch sauber zu messen; einen Anstieg nach dem Ende der Sperre
behaupten wir deshalb nicht. Außerdem wechselte während der Studie, welche
KI-Anbieter gemessen wurden. Und die Besucherzahlen der Website wurden damals nicht
gespeichert — der Anstieg nach dem viralen Reddit-Beitrag lässt sich aus den
Protokollen daher nicht belegen.
10
Was das für die AEO-/GEO-Praxis bedeutet
- Crawler-Zugang ist nicht der Hebel. Die Seite war 22 Tage für KI-Bots blockiert, und Sichtbarkeit entstand trotzdem — über Wissensgraph + strukturierte Identität. Prüfe deinen Cloudflare-KI-Bot-Standard.
- „Für KI optimieren" ist kein einzelnes Ziel. Provider-Divergenz dominiert — wähle den Anbieter, den dein Publikum nutzt, und miss genau den.
- Präzision > Präsenz. Ein Modell, das dich halluziniert, ist schlimmer als eines, das dich auslässt. Verfolge die Halluzinations-Rate, nicht nur die Trefferquote.
- Strukturierte Identität ist der schnelle Hebel; soziale Reichweite ist langsam — und bringt Leser, keine KI-Zitationen. Verwechsle die beiden nicht.
11
Daten & Reproduktion
Vor-Registrierung 10.5281/zenodo.20125967 · Methoden-Notiz 01 10.5281/zenodo.20125933 · offener Datensatz (~16k bewertete Zeilen) huggingface.co/datasets/marintkael/ai-citation-fidelity · Werkzeuge (MIT) github.com/marintkael/marin-research-tools · Live-Daten Research-Dashboard · ORCID 0009-0006-2105-8190.
Begriffsklärung. Dies ist computerlinguistische / KI-Such-Forschung. „Marin" ist der Name des Autors — keine Meeres-, Schifffahrts- oder Ozeanographie-Forschung, ohne Bezug zu MARIN (Maritime Research Institute Netherlands). Lizenz CC-BY-4.0.
12
Literatur
- Aggarwal, P., Murahari, V., Rajpurohit, T., Kalyan, A., Narasimhan, K., & Deshpande, A. (2023). GEO: Generative engine optimization (arXiv:2311.09735). arXiv. arxiv.org/abs/2311.09735
- Chen, M., Wang, X., Chen, K., & Koudas, N. (2025). Generative engine optimization: How to dominate AI search (arXiv:2509.08919). arXiv. arxiv.org/abs/2509.08919
- Schulte, J., Bleeker, M., & Kaufmann, P. (2026). Don't measure once: Measuring visibility in AI search (GEO) (arXiv:2604.07585). arXiv. arxiv.org/abs/2604.07585
- Yeh, M.-H., Kamachee, M., Park, S., & Li, Y. (2025). HalluEntity: Benchmarking and understanding entity-level hallucination detection (arXiv:2502.11948). arXiv. arxiv.org/abs/2502.11948
- Zhao, W., Goyal, T., Chiu, Y. Y., Jiang, L., Newman, B., Ravichander, A., Chandu, K., Le Bras, R., Cardie, C., Deng, Y., & Choi, Y. (2024). WildHallucinations: Evaluating long-form factuality in LLMs with real-world entity queries (arXiv:2407.17468). arXiv. arxiv.org/abs/2407.17468