Field Report · AI Citation Behaviour Lab
Zero to Cited in Six Days.
How a brand-new author entity became AI-visible in 23 days — while every AI crawler was blocked at the door.
Summary
We put a brand-new pseudonymous author identity online for the first time — no published book, no reviews, no press — and measured, daily across five large-language-model surfaces and eleven observation channels, exactly when and how it became visible to AI answer engines. Five results, none of which the prevailing "AI-SEO / GEO" playbook predicts: (1) Speed — invisible to correctly cited by a web-augmented frontier model in six days; in the Google Knowledge Graph by day four. (2) A locked door, and it didn't matter — for 22 of 23 days Cloudflare blocked every AI crawler with HTTP 403 (its opt-out default), and the entity became visible anyway, proving the visibility runs through the Knowledge Graph and inference-time grounding, not crawling or training. (3) A provider chasm, not a capability ladder — one provider is precise (≈4.7 correct citations per hallucination), another hallucinates twice as often as it's right. (4) Where it lands, it lands deep. (5) Structured identity moves the needle; social reach (so far) doesn't. Single-subject, pre-registered, open data.
Keywords Generative Engine Optimization · Answer Engine Optimization · LLM citation · AI search visibility · Knowledge-Graph propagation · entity disambiguation · LLM hallucination · llms.txt · AI-crawler blocking · single-subject study
1
Setup
AI answer engines (ChatGPT Search, Perplexity, Gemini, Copilot, AI Overviews) increasingly decide how authors and works are found. An entire practitioner industry sells methods to become visible there — almost none measured under control, because you cannot run a clean before/after on an entity that already exists. So we built one. A net-new entity is the ideal instrument: at T+0 it has zero prior presence, so every later signal is attributable to a documented intervention, not pre-existing fame.
- Subject: a pseudonymous fantasy author, debut novel scheduled for 22 Sept 2026 — no published work exists during the window.
- T+0: 11 May 2026 (domain + identity programme launched same day).
- Inputs (identity engineering only): Wikidata person + work items, ORCID, Schema.org JSON-LD, Zenodo DOIs, a GitHub repo, low-volume Reddit/Bluesky/Hardcover presence. No content marketing, no paid promotion, no book.
- Apparatus: 5 LLM surfaces, 16 standardized probe questions in 6 categories, polled daily; plus knowledge-graph, search-index, crawler-log and social channels. ~16,000 scored datapoints.
Full method in Methodology Note 01 (Zenodo); pre-registration 10.5281/zenodo.20125967. Live daily data: research dashboard.
2
Finding 1 — Zero to Cited in Six Days
Four days of flat 0 % — the entity did not exist for the models — then a fast breakthrough. The Knowledge-Graph match (T+4) preceded the first LLM citation (T+6) by two days, consistent with structured identity → knowledge graph → answer-engine citation. Google indexed 25 of 30 URLs (83 %) by T+23. For an entity that did not exist three weeks earlier, this contradicts the common AEO/GEO assumption that LLM citation presupposes an established corpus — the big-brand bias toward incumbents over niche players that the GEO literature documents (Chen et al., 2025).
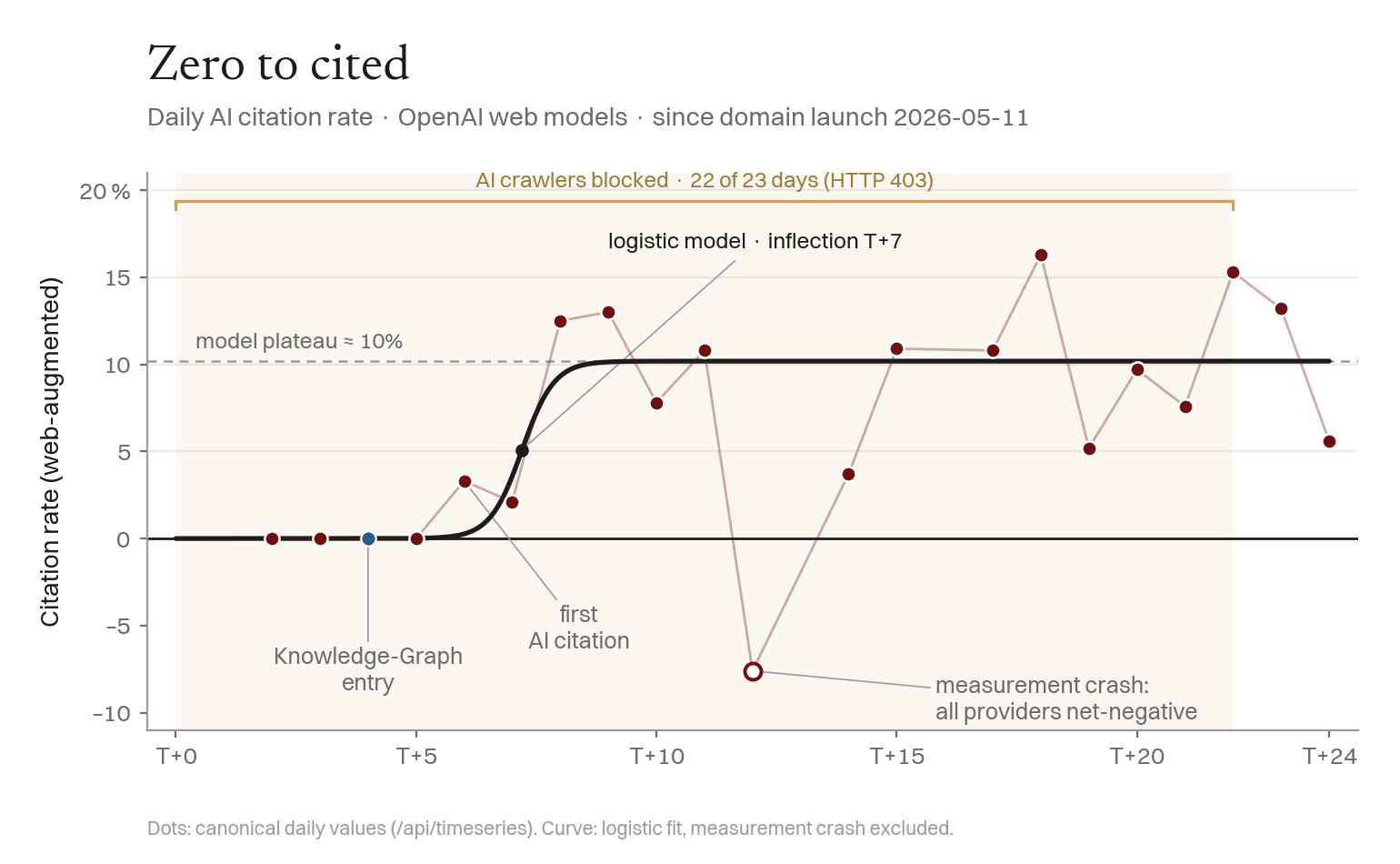
3
Finding 2 — Visibility Through a Locked Door
The most counterintuitive result, and an accidental but clean natural experiment. For 22 of the 23 days, Cloudflare's "Block AI training bots" was set to "Block on all pages" — every AI crawler (GPTBot, ClaudeBot, CCBot, Google-Extended) was rejected with HTTP 403 before it could read the site. This was never chosen: it is Cloudflare's opt-out default for new domains since "Content Independence Day" (July 2025), silently armed at setup.
So the site's front door was locked to AI crawlers for almost the entire window — yet the entity entered the Knowledge Graph (T+4) and earned correct citations (T+6) regardless. The conclusion is forced:
The AI visibility did not come from crawling or training the website — that was blocked. It came from the Knowledge Graph (Wikidata, untouched by the site block) and inference-time grounding on third-party mentions.
Source-grounding on the official domain ran at a constant ~24/day
throughout the block (575 attributions total). This is the sharpest
possible refutation of the common GEO advice that AI visibility comes mainly
from giving crawlers access to your own site — here it literally could not, for
22 days, and it worked anyway. It matches Chen et al. (2025), who show that
AI search systematically favors earned media (authoritative third-party
sources) over brand-owned content.
(Honest limit: because crawlers were blocked, this dataset can say nothing
about llms.txt efficacy — the zero AI-crawler hits in our
logs were blocked, not "ignoring the file.")
4
Finding 3 — A Provider Chasm, Not a Capability Ladder
The assumption that more capable models are more reliable is wrong for novel entities. What separates citation from hallucination is which provider. Precision = correct citations per hallucination (7-day window): OpenAI's web models run 4.7 : 1; Gemini runs 0.47 : 1 — it hallucinates twice as often as it gets it right; Claude (all tiers, web) is net-negative — with an important caveat (see below).
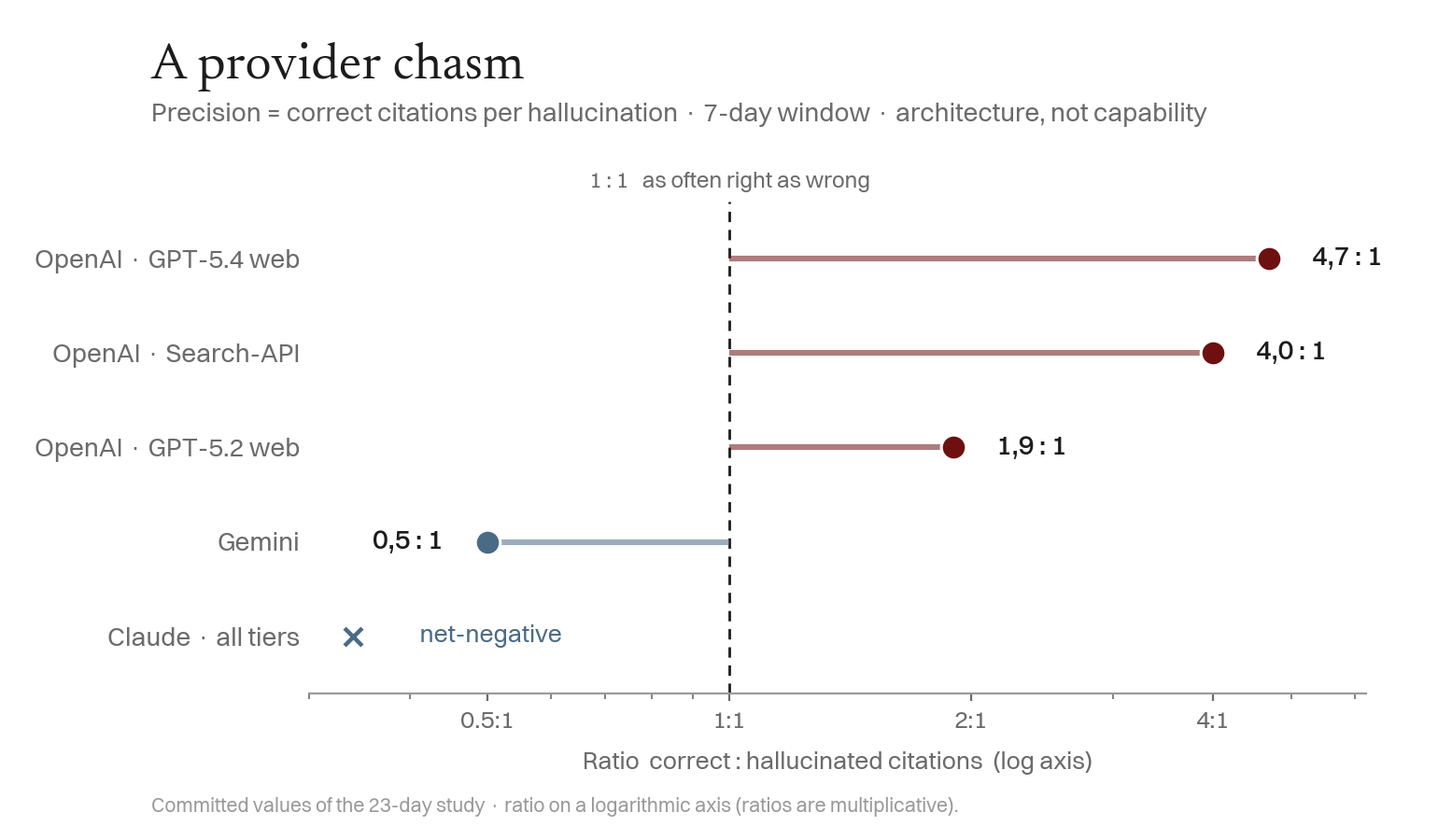
Caveat on Claude (construct validity, exploratory). A post-hoc re-analysis qualifies this picture: we re-read the full Claude answers, web-verified their claims, and validated a classifier against a manual sample (n = 50, Cohen's κ = 0.79, recall 100%). Of the 176 responses the automatic scorer flagged as Claude hallucinations, only about 11% (95% CI 7–16%) are genuine — and all of those are minor linguistic substitutions (reading Marin as marine), not fabricated author biographies. The rest are correct: either disambiguation of a real name collision (Das vierte Feld is a 1999 book by Mokka Müller; Marin collides with the Maritime Research Institute Netherlands) or accurate answers naming real books (e.g. SERAPH-2026 titles). The collision both occludes the entity and corrupts the automated scoring. The raw scores stay for consistency with the pre-registration; this correction is exploratory.
The source choice explains it. When correctly attributed, the dominant source is the entity's own domain. But providers differ in what they reach for: OpenAI's frontier model grounds on the official site 119×; Gemini grounds on it 0× and pulls the entity only from Reddit (17/17). Provider divergence is mechanically a retrieval-source divergence.
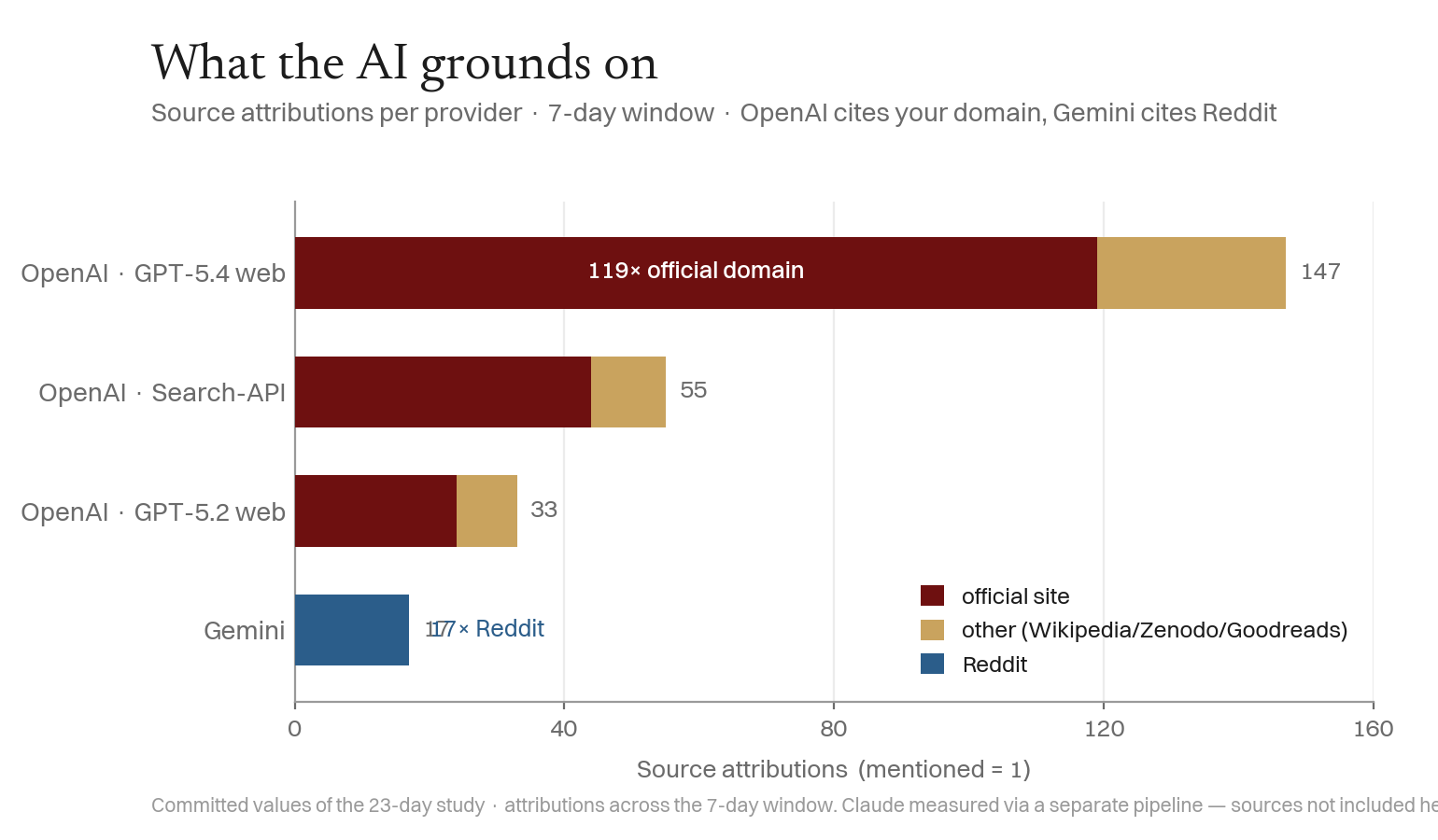
Two structural reasons reinforce this: the entity has no Wikipedia page the whole time — and Zhao et al. (2024) show in WildHallucinations that LLMs hallucinate consistently more for entities without a Wikipedia page, so the confabulation is literature-expected. And Bing only began crawling on T+17; the citation peak fell one day later — a plausible Bing-index → OpenAI-citation trail.
5
Finding 4 — Semantic Depth Where It Lands
A low average hit-rate hides the quality where it lands. When OpenAI finds the entity, the description is fully correct and deep (verbatim):
"‚Das vierte Feld' is a forthcoming epic fantasy novel by Marin T. Kael and the first volume of the series ‚Prägungen des Reiches'. Per the author's site it releases 22 September 2026." … "Varin is the central setting — the ‚Realm of Edicts'." … "Marin T. Kael is the pseudonym of a German-language fantasy author and also a researcher, running an open project on author visibility through AI…"
Data exhibit — verbatim excerpts from three OpenAI answers (GPT, web search), retrieved through T+23; ellipses mark omissions.
That is a complete, correct, source-grounded entity model after 23 days —
series, setting, release date, even the pseudonym status and research project.
The live mechanism is visible in the cited URL itself:
marin-t-kael.de/buch?utm_source=openai — fetched live, not recalled
from training.
6
Finding 5 — What Moves the Needle, and What Doesn't (Yet)
Laying daily account-activity beside daily findability reveals an uncomfortable, useful result: the social activity did not drive the AI visibility. The citation breakthrough (17 May) came before the Reddit-karma build; a 23× karma jump (12 → 281, 23–26 May) produced no citation lift. The Knowledge-Graph score sat constant at 43; Bing inlinks = 0.
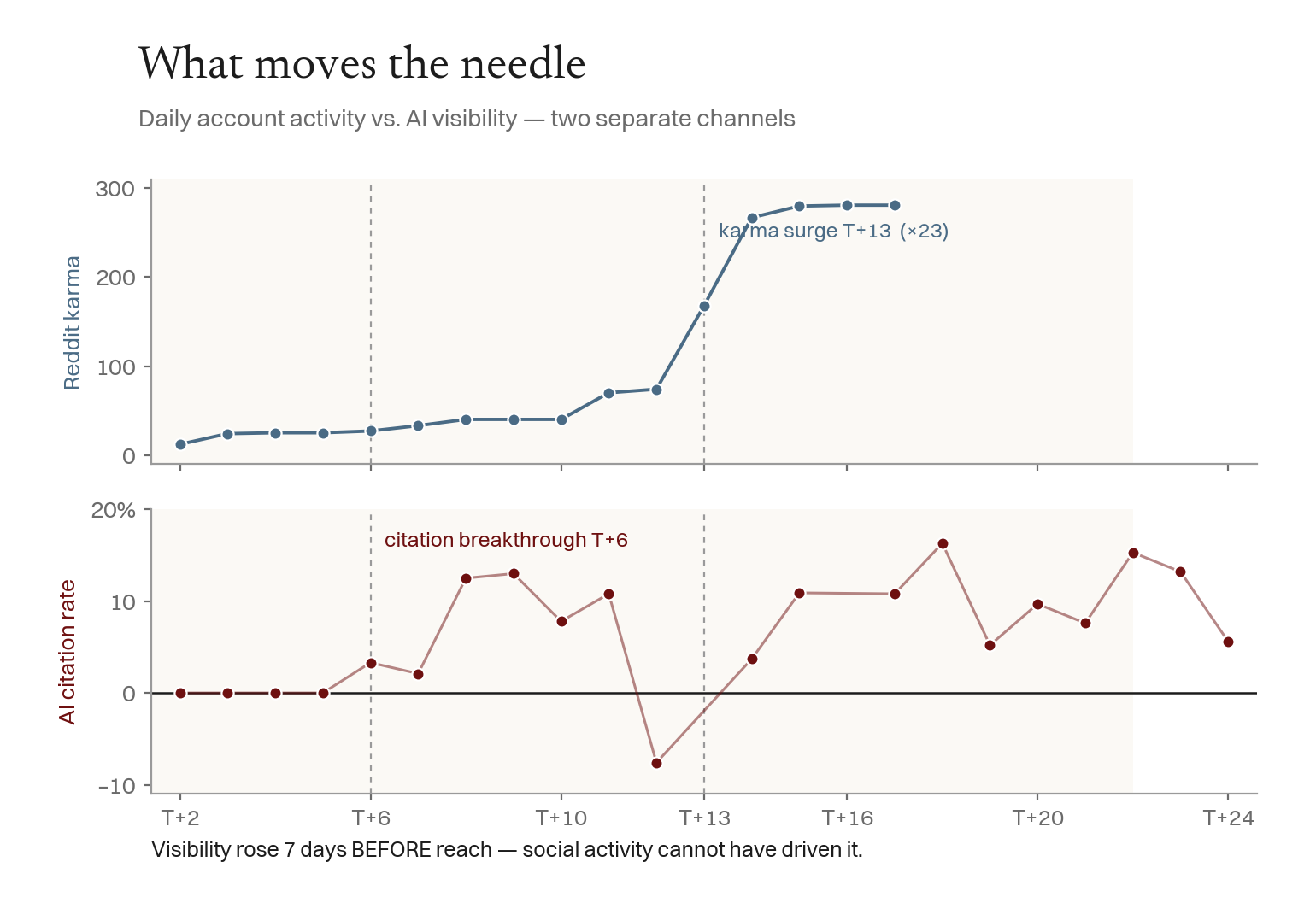
Crucially — "no AI lift" is not "no effect"; it is the wrong channel. When the Reddit post went viral (24–25 May, post-karma 1 → 132 in two days), it drove human website traffic — direct visitors, not model citations — while the citation rate stayed flat (6–10 %) straight through it. Social virality and AI visibility are separate channels: the former buys readers, the latter is bought by structured identity. Conflating them is the central confusion in GEO marketing. (Caveat: the Reddit lever is a pre-registered 90-day intervention, so "no correlation in 23 days" means "too early," not "ineffective.")
7
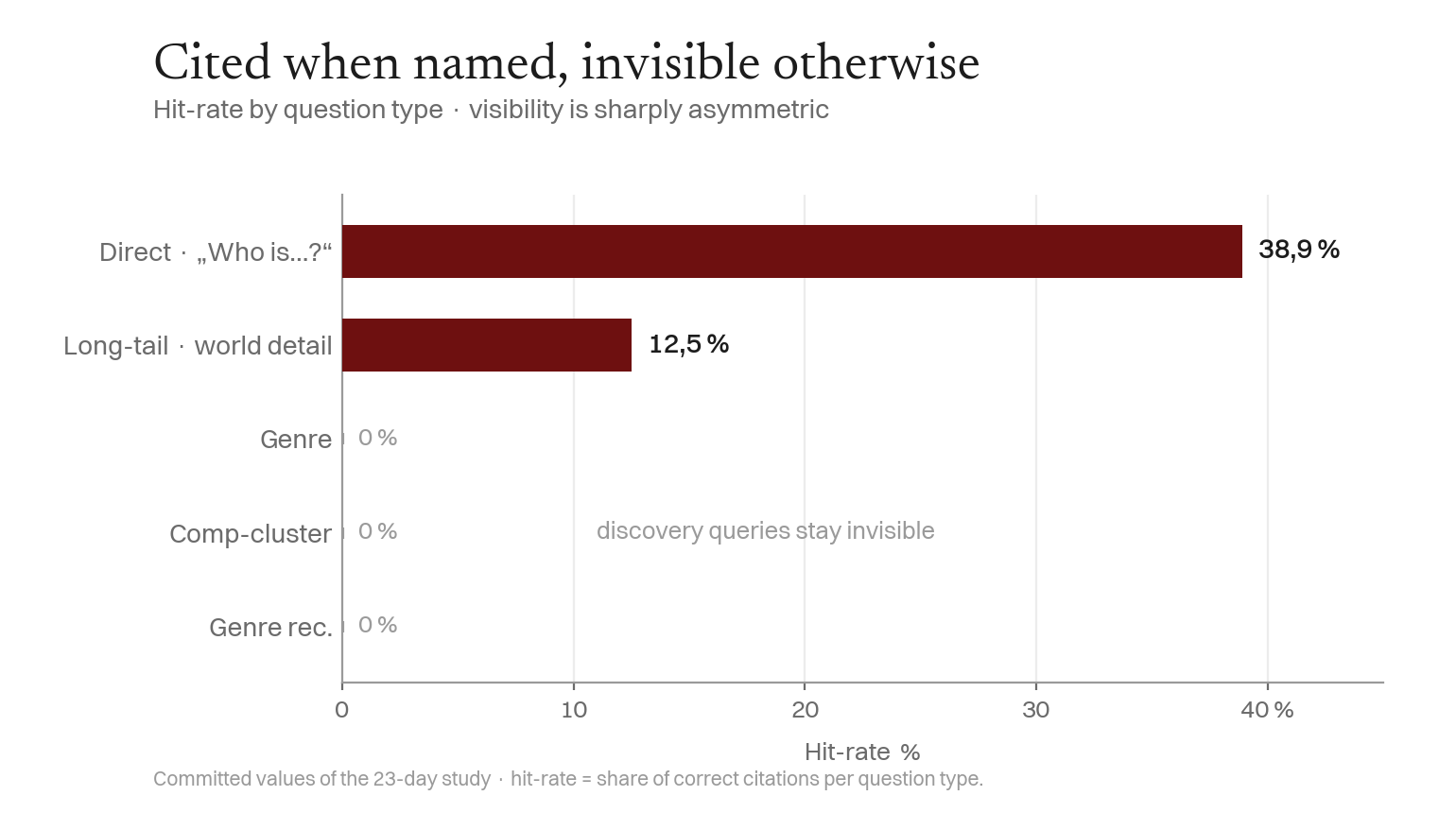
Finding 6 — Cited When Named, Invisible Otherwise
Visibility is wildly asymmetric by question type. Named ("Who is Marin T. Kael?"), a frontier model resolves it ~4 in 10 — remarkable at three weeks. Unprompted, in a genre or recommendation context, it is invisible (0 %) — and search-analytics confirms 0 clicks / 0 impressions of organic search traffic. Identity engineering buys recall on demand, not discovery.
8
In Context — How Fast Is "Six Days", Really?
Two honest caveats: there is no peer-reviewed baseline for crawl-latency or knowledge-graph-establishment time (those are convergent industry experience), and no study measures "days to first LLM citation for a net-new entity" — making T+6 an original data point.
| Dimension | Measured | Normal expectation |
|---|---|---|
| Knowledge-Graph entry | T+4 | 3–12 months from Wikidata (practitioner) |
| Site crawled & indexed | T+7–10 (25/30 by T+23) | 1–4 weeks typical (practitioner) |
| First LLM citation | T+6 | no baseline — the gap |
| Hallucination of a thin entity | Gemini 0.47:1; Claude negative (collision artifact) | more for entities w/o Wikipedia page (Zhao et al., 2024) |
KG entry in four days against a 3–12-month norm is one-to-two orders of magnitude faster than expected — and it happened while crawlers were blocked, which is the headline.
9
Limitations
Single subject, one language-primary, one genre — not statistically generalisable. Subject = investigator (conflict of interest; mitigated by pre-registration + public failure log). The AI-crawler block confounds any llms.txt conclusion. Wikidata was unstable (original QIDs deleted by RfD; current ones recent). The block lifted only at T+22 — too recent to measure its effect; no clean post-lift jump is claimed. Provider roster changed mid-study. Website traffic was not persisted at the time, so the viral-post traffic spike could not be quantified from logs.
10
What this means for AEO / GEO practice
- Crawler access is not the lever. The site was blocked to AI bots for 22 days and visibility happened anyway — via Knowledge Graph + structured identity. Check your Cloudflare AI-bot default.
- "Optimize for AI" is not one target. Provider divergence dominates — pick the provider your audience uses and measure that one.
- Precision > presence. A model that hallucinates you is worse than one that omits you. Track hallucination rate, not just hit-rate.
- Structured identity is the fast lever; social reach is slow — and buys readers, not AI citations. Don't conflate the two.
11
Data & Reproduction
Pre-registration 10.5281/zenodo.20125967 · Methodology Note 01 10.5281/zenodo.20125933 · open dataset (~16k scored rows) huggingface.co/datasets/marintkael/ai-citation-fidelity · tooling (MIT) github.com/marintkael/marin-research-tools · live data research dashboard · ORCID 0009-0006-2105-8190.
Disambiguation. This is computational-linguistic / AI-search research. "Marin" is the author's name — not marine, maritime or oceanographic research, and unrelated to MARIN (Maritime Research Institute Netherlands). Licensed CC-BY-4.0.
12
References
- Aggarwal, P., Murahari, V., Rajpurohit, T., Kalyan, A., Narasimhan, K., & Deshpande, A. (2023). GEO: Generative engine optimization (arXiv:2311.09735). arXiv. arxiv.org/abs/2311.09735
- Chen, M., Wang, X., Chen, K., & Koudas, N. (2025). Generative engine optimization: How to dominate AI search (arXiv:2509.08919). arXiv. arxiv.org/abs/2509.08919
- Schulte, J., Bleeker, M., & Kaufmann, P. (2026). Don't measure once: Measuring visibility in AI search (GEO) (arXiv:2604.07585). arXiv. arxiv.org/abs/2604.07585
- Yeh, M.-H., Kamachee, M., Park, S., & Li, Y. (2025). HalluEntity: Benchmarking and understanding entity-level hallucination detection (arXiv:2502.11948). arXiv. arxiv.org/abs/2502.11948
- Zhao, W., Goyal, T., Chiu, Y. Y., Jiang, L., Newman, B., Ravichander, A., Chandu, K., Le Bras, R., Cardie, C., Deng, Y., & Choi, Y. (2024). WildHallucinations: Evaluating long-form factuality in LLMs with real-world entity queries (arXiv:2407.17468). arXiv. arxiv.org/abs/2407.17468